mapping保存的是索引的结构,类似于数据库中的表结构,索引里面有哪些字段、字段是什么类型,用什么分析器等等这些信息都保存在 mapping 中。 查询 mapping 结构如下:
GET /customer/_mapping?pretty
{
"customer": {
"mappings": {
"properties": {
"address": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"age": {
"type": "long"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
我们在前面向索引中插入文档的时候,并没有事先制定索引里面字段的结构类型,这是因为 ElasticSearch 会自动根据数据的值反推出字段的类型,自动创建 mapping。
创建 mapping
第一种方式是在创建索引的时候指定mapping
PUT my_index
{
"mappings": {
"properties": {
"title": { "type": "text" },
"name": { "type": "text" },
"age": { "type": "integer" },
"created": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
}
}
}
}
# 返回
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "my_index"
}
如果是已经创建好的索引,如何给索引加mapping呢?
PUT /my_index/_mapping/
{
"properties": {
"email": {
"type": "keyword"
}
}
}
对于已经存在的字段是没法更新mapping的,例如 age 是int类型,你就没法修改成 str 了。你只能增加字段,不过以下几种属于特殊情况:
假设username的类型是对象类型,有一个first属性
{
"properties": {
"username": {
"properties": {
"first": {
"type": "text"
}
}
}
}
}
对于username字段,因为它的类型属于对象类型,所以你还可以给他继续添加属性 last。
{
"properties": {
"username": {
"properties": {
"last": {
"type": "text"
}
}
}
}
}
mapping 属性
创建mapping时,我们接触了 properties、type 属性,其实它还有很多属性,分为一级、二级、三级。比如我们给某个字段指定分析器的属性就属于三级属性。
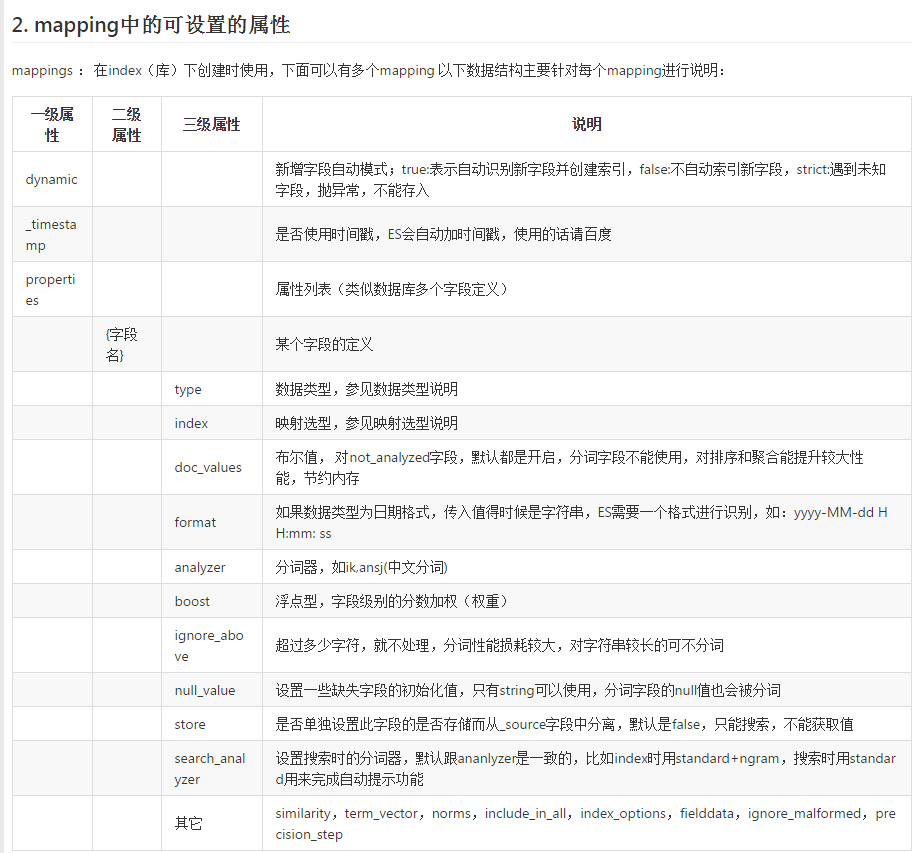
给字段指定分析器
给字段 name 指定 ik_smart 分词器
PUT /my_index2
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
# 还可以指定为keyword形式,如果keyword超过256,自动忽略
# {"type": "text", "fields": {"keyword": {"type": "keyword", "ignore_above": 256}}
# 添加数据
PUT /my_index2/_doc/1
{ "name": "现在年轻人是迷失,还是迷茫" }
PUT /my_index2/_doc/2
{ "name": "深度调查丨李晓江事件背后:美国处罚华人科学家的真实逻辑" }
# 搜索
当type为keyword时,这时无法在指定analysis, 如果要指定analysis 可以将类型指定为 text。 analysis 使用 keyword lowcase token filter。
https://my.oschina.net/davidzhang/blog/811511
关注公众号「Python之禅」,回复「1024」免费获取Python资源
