要使用好 Elasticsearch,有几个概念你不得不弄清楚。
Node 、 Cluster
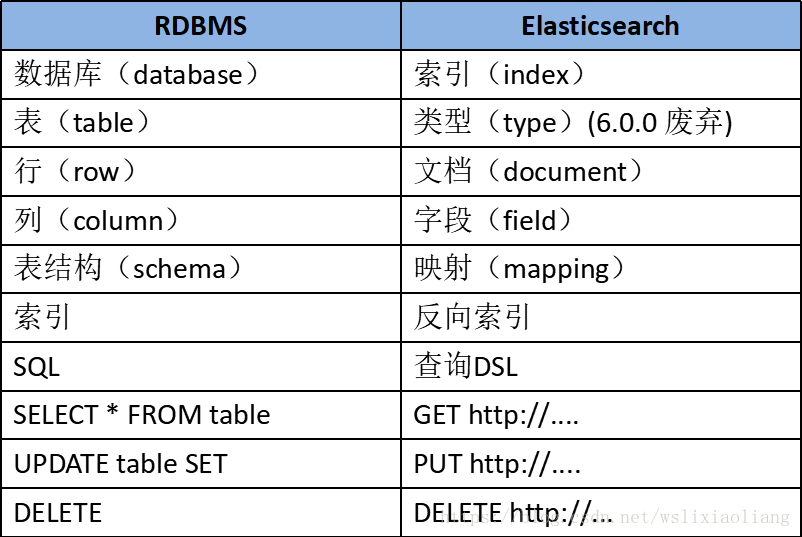
Elasticsearch 本质上是一个分布式数据库,单个 Elasticsearch 实例称为一个节点(node),一组节点构成一个集群(cluster)。
索引(index)
Elasticsearch 的索引类似于巨大的字典结构,保存了关键字到文档记录之间的映射关系, 也称为倒排索引,索引使得 Elasticsearch 支持快速检索,ElasticSearch 将不同数据存储在不同索引(index)中。例如订单数据放在订单索引,用户数据放在用户索引中,如果类比 MySQL,索引就像数据库,可以向索引写入文档或者从索引中检索文档、更新文档、删除文档等操作。
文档(Documents)
文档可以理解为一条数据记录,例如一条订单记录,一条用户记录,都叫一个文档,文档用JSON 格式表示,文档可以由多个字段组成,例如一条用户记录中有名字、性别、地址等信息,在一个索引中可以存储无数个文档。
分片和副本(Shards & Replicas)
分片和副本都是分布式系统中的概念,分片是为了解决单节点故障问题,可以将索引中的数据拆分在不同节点的多个分片(Shads)中,使得数据可以横向扩展,多个 shards 分布式并发的操作,从而提升整体性能和吞吐量。
副本(Replicas)是为了解决容错而设计的高可用方案,数据如果只存储一份有可能导致数据丢失,为此,同一一份数据保留多个副本确保的数据的高可用性。
参考文档:
- https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started-concepts.html
- https://www.elastic.co/blog/a-practical-introduction-to-elasticsearch
- https://www.elastic.co/guide/index.html
关注公众号「Python之禅」,回复「1024」免费获取Python资源
