阮一峰老师对普及计算机基础技术功不可没,但毕竟老师不是神,因此也避免不了对某些概念有一些错误的理解,《字符编码笔记:ASCII,Unicode 和 UTF-8 》 是阮老师10年前写的一篇关于字符编码的科普文章,现在用 Google 搜关键字该文章依然名列前茅,可见他的文章有多大影响力,不过这是后话,但里面的内容是否正确是值得商榷的事。
话说天下大势,分久必合,合久必分,在字符编码世界里也遵循这样一种历史规律。从 ASCII 码到 EASCII(ISO8859),发展到后来的群雄并起,各国家地区拥有自己的编码格式,中国有 GBK,日本有 JIS,台湾有 BIG5,然而这是一个混战的年代,大家各自为政,没有统一的编码标准,交流起来极其麻烦。字符编码成为了程序员最头疼的问题之一
于是在 1991 年,国际标准化组织和统一码联盟组织各自开发了 ISO/IEC 10646(USC)和 Unicode 项目。他们两的野心都不小,一统江湖,千秋万载。不过很快双方都意识到世界上并不需要两个不兼容的字符集。于是他们就编码问题进行了一次非常友好地会晤,决定彼此把工作内容合并,项目还是独立存在,各自发布各自的标准,前提是两者必须保持兼容。不过由于 Unicode 这一名字比较好记,因而它使用更为广泛,成为了事实上的统一编码标准。
以上是对字符编码历史的一个简要回顾,Unicode 究竟是什么东西,它是一种编码格式吗?中文维基百科对 Unicode 的解释也是让人一头雾水,摸不着头脑。那么来看看阮老师怎么说:
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是Unicode,就像它的名字都表示的,这是一种所有符号的编码。
这句话读起来很拗口,有三个地方出现了「编码」二字。不知阮老师对「编码」的理解是什么?但可以肯定的是这三个「编码」在这句话里面不是同一个意思。因此有必要先解释一下「编码」到底是什么意思。
「编码」在汉语里可以作动词使用,编码就是把一个字符(严格一点说是字符在字符集中的编号 code point)转换成一个字节序列,以便在网络传输或者存储到文本中。比如「好」在 Unicode 中的编号是 U+597d,经过 UTF-8 编码后会转换成二进制序列是 '\xe5\xa5\xbd' 。
>>> a = u"好"
>>> a
u'\u597d'
>>> b = a.encode("utf-8")
>>> b
'\xe5\xa5\xbd'
>>>
「编码」还可以做名词使用,作为名词使用时,就是指一种具体的编码实现方式,比如 ASCII 编码,GBK 编码,UTF-8 编码,都叫做编码,是一种具体的实实在在的编码格式。
把编码概念弄清楚了之后,我们就可以来定义 Unicode 了。其实 Unicode 是一个囊括了世界上所有字符的字符集,其中每一个字符都对应有唯一的编码值(code point),然而它并不是一种什么编码格式,仅仅是字符集而已。 Unicode 字符要存储要传输怎么办,它不管,具体怎么编码,你们可以自己去实现,可以用 UTF-8、UTF-16、甚至用 GBK 来编码也是可以的。比如:
>>> a = u"好"
>>> a
u'\u597d'
>>> b = a.encode("gbk")
>>> b
'\xba\xc3'
「好」用 GBK 编码转后就是用两个字节表示,用 UTF-8 编码就是 3 个字节,同一个字符用不同的编码方式占用的字节长度不一。
阮老师谈到 Unicode 的问题 时说:
这里就有两个严重的问题,第一个问题是,如何才能区别 Unicode 和 ASCII ?
把 Unicode 和 ASCII 码作为字符集来理解时,需要区分二者吗?不需要,因为 Unicode 是在 ASCII 的基础之上建立的,比如 ASCII 码字符集中的 「A」对应的 code ponit 是 0x41,Unicode 码是 U+0041,两者是一样的。至于中日韩文字用 ASCII 根本没法表示,所以也不存在混淆的说法。他又接着说:
计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?
计算机怎么不知道是用几个字节表示呢?你把字符存储到文本的时候肯定是要指定一种编码格式的,既然指定了编码格式,那么读取的时候也按照该种编码格式反过来读就行了。老师把这也当做一个问题就有点牵强附会了。
再来看阮老师说 Unicode 的第二个问题:
第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
Unicode 并没有统一规定每个符号用三个或者四个字节表示。Unicode 只规定了每个字符对应到唯一的代码值(code point),代码值 从 0000 ~ 10FFFF 共 1114112 个值 ,真正存储的时候需要多少个字节是由具体的编码格式决定的。比如:字符 「A」用 UTF-8 的格式编码来存储就只占用1个字节,用 UTF-16 就占用2个字节,而用 UTF-32 存储就占用4个字节。
再看来看这张图:
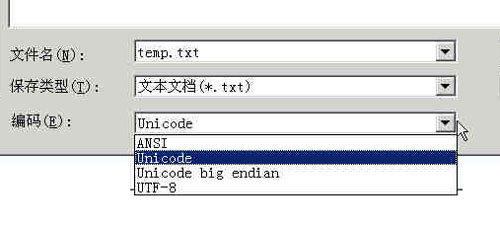
阮老师对 Unicode 编码的解释是:
Unicode编码指的是UCS-2编码方式,即直接用两个字节存入字符的Unicode码。这个选项用的little endian格式。
阮老师全文并没有对 UCS-2 做任何解释,导致很多读者非常疑惑,因此,我有必要在这里解释一下。
UTF( Unicode Transformation Format)编码 和 USC(Universal Coded Character Set) 编码分别是 Unicode 、ISO/IEC 10646 编码体系里面两种编码方式,UCS 分为 UCS-2 和 UCS-4,而 UTF 常见的种类有 UTF-8、UTF-16、UTF-32。因为两种字符集是相互兼容的,所以这几种具体的编码格式也有着对应的等值关系。
UCS-2 是使用两个定长的字节来表示一个字符,UTF-16 也是使用两个字节,不过 UTF-16 是变长的(网上很多错误的说法说 UTF-16是定长的),遇到两个字节没法表示时,会用4个字节来表示,因此 UTF-16 可以看作是在 UCS-2 的基础上扩展而来的。而 UTF-32 与 USC-4 是完全等价的。
再回到这张图片,之所以在 Windows下有 Unicode 编码这样一种说法,其实是 Windows 的一种错误表示方法,或许是因为历史原因还是其他问题一直沿用至今。这因为如此,导致绝大多数初学者误以为 Unicode 就是一种编码格式,所以 Windows 有时也是误人子弟啊。反正你就理解为 UTF-16 编码就是。
阮老师对什么是大端和小端的解释显得很唐突。为什么会有大端小端?也解释的含糊其词:
上一节已经提到,Unicode码可以采用UCS-2格式直接存储。以汉字"严"为例,Unicode码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,就是Big endian方式;25在前,4E在后,就是Little endian方式。因此,第一个字节在前,就是"大头方式"(Big endian),第二个字节在前就是"小头方式"(Little endian)。
小端就是低位字节放在内存的低地址端,高位字节放在内存的高地址端。与之相反,大端就是高位字节放在内存的低地址端,低位字节放在内存的高地址端。举例来说,字节序列 '0x12 34 56 78' 在内存中的表示形式为:
# 小端模式
低地址 ------------------> 高地址
0x78 | 0x56 | 0x34 | 0x12
# 大端模式
低地址 -----------------> 高地址
0x12 | 0x34 | 0x56 | 0x78
至于为什么会有大端和小端之分呢?对于 16 位或者 32 位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节排放的问题,因为不同机器类型读取双字节的时候方式不一样,因此就导致了大端存储模式和小端存储模式的存在,两者并没有孰优孰劣。
前面我已经解释过了 UCS-2 可以理解为 UTF-16 编码,汉字「严」的 Unicode 编号是 U+4E25,存储的时候到底需要几个字节,跟具体的编码格式有关,如果是用 UTF-8 编码,结果为 'e4 b8 a5',需要 3 个字节来存储。用 UTF-16 编码,结果为 '4e 25',用两个字节存储,UTF-32 就要用4个字节了。因为 UTF-16 和 UTF-32 都是以双字节为单位来储存字符的,双字节就存在大小端的问题了。而 UTF-8 的编码单元是1个字节,所以就不用考虑字节序问题。
他又说:
Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(ZERO WIDTH NO-BREAK SPACE),用FEFF表示。这正好是两个字节,而且FF比FE大1。
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式
这里就错得有点离谱了。在 UTF-16 中,FEFF 是字节顺序标记(byte order mark,BOM),用来标记编码后的字节序列高位在前还是低位在前。小端低位在前,高位在后,用 「FFFE」 标识。大端高位在前,低位在后,用 「FEFF」 标识。

上图就是我分别用 UTF-16LE(小端)和 UTF-16BE(大端)保存的「严」的十进制显示方式。而 FEFF 作为零宽度非换行空格仅仅是它出现在字节序列的中间时的作用,用户看起来就是一个空格,不过从 Unicode3.2 开始就只能规定 FEFF 只能出现在字节流的开头,用于标记字节序(大小端)。
最后是我自己的补充,UTF-8、UTF-16 各自的应用场景和优缺点。
UTF-8 的优势是:它以单字节为单位用 1~4 个字节来表示一个字符,兼容了 ASCII,在数据传输和存储过程中节省了空间,其二是UTF-8 不需要考虑大小端问题。这两点都是 UTF-16 的劣势。
不过对于中文字符,用 UTF-8 就要用3个字节,而 UTF-16 只需2个字节。而UTF-16 的优点是在计算字符串长度,执行索引操作时速度会很快。Java 内部使用 UTF-16 编码方案。而 Python3 使用 UTF-8。UTF-8 编码在互联网领域应用更加广泛。
以上就是我对字符编码的一点个人理解,不一定全部正确,但希望同样能给你带来一些思考。阮一峰老师的这篇文章虽然有些错误的地方,但只要不盲崇,带着怀疑的态度看待问题,也一定有不一样的收获。
参考链接:
- https://en.wikipedia.org/wiki/Unicode
- https://en.wikipedia.org/wiki/UTF-32
- https://en.wikipedia.org/wiki/UTF-16
- https://zh.wikipedia.org/wiki/%E4%BD%8D%E5%85%83%E7%B5%84%E9%A0%86%E5%BA%8F%E8%A8%98%E8%99%9F
- https://zh.wikipedia.org/wiki/%E9%80%9A%E7%94%A8%E5%AD%97%E7%AC%A6%E9%9B%86
- https://en.wikipedia.org/wiki/Universal_Coded_Character_Set
- http://unicode.org/faq/utf_bom.html
- http://www.fmddlmyy.cn/text6.html
- http://stackoverflow.com/questions/643694/utf-8-vs-unicode
- http://stackoverflow.com/questions/700187/unicode-utf-ascii-ansi-format-differences
- https://www.meridiandiscovery.com/articles/unicode-and-character-encodings/
- https://www.praim.com/character-encodings-linux-ascii-utf-8-iso-8859
- http://stackoverflow.com/questions/4655250/difference-between-utf-8-and-utf-16
- http://www.guokr.com/blog/83367/
关注公众号「Python之禅」,回复「1024」免费获取Python资源
