上篇文章 Python装饰器为什么难理解?从函数到装饰器一步一步介绍了Python装饰器的来由,不知你对装饰器理解了没有,强烈建议你自己动手写个装饰器应用到项目中加深理解。装饰器可以很简单,也可以很复杂,具体看业务场景,简单装饰器不带任何参数,而带参数的装饰器则更灵活,还有一种更为复杂的叫类装饰器。
哪些地方适合用装饰器呢?但凡是在多个地方出现雷同的代码块,且这些代码与核心业务没有直接关联的都可以用装饰器来代替,装饰器不仅能减少代码量,还使得代码逻辑更清晰、可读性更强,你只需专注于业务逻辑处理就行了。
今天说说带参数的装饰器,为了简化业务逻辑,我们实现字符串大写转换的需求,重点关注装饰器部分:
# 业务函数
def my_upper(text):
value = text.upper()
return value
print(my_upper("hello")) # HELLO
现在需求有变更,核心业务不变,但是需要对转换的的字符包裹一层HTM标签,输出如: <p>HELLO</p>,最简单的办法就是直接在函数里面修改逻辑,如:
def my_upper(text):
value = text.upper()
return "<p>" + value + "</p>"
又接到产品通知,需求有变更,还要在外面套一个div,于是你很不情愿地回去再修改:
def my_upper(text):
value = text.upper()
return "<div><p>" + value + "</p></div>"
如何应对产品这种无止境的修改呢?

玩笑开完了,技术还是要为业务服务啊,那我们就想一个可以灵活应对产品的办法吧,这里,装饰器就是一个很好的方案。最终效果应该是这样:
@tag("p")
def my_upper(text):
value = text.upper()
return value
print(my_upper("hello")) #<p>HELLO</p>
如何实现呢?先从简单装饰器开始,实现一个不带参数的装饰器
def tag(func):
def wrapper(text):
value = func(text)
return "<p>" + value + "</p>"
return wrapper
@tag
def my_upper(text):
value = text.upper()
return value
调用
print(my_upper("hello")) # <p>hello</p>
@tag 语法糖等价于 my_upper = tag(my_upper)
my_upper("hello") 等价于 wrapper("hello") 尽管你不能直接访问wrapper,但可以这样去理解
使用装饰器,业务代码一行的都没改,只需要在函数定义处加上装饰器,就实现了相同的功能,那么如何更灵活地通过参数来指定输出的样式呢?使用带参数的装饰器
带参数的装饰器
带参数的装饰器只需要在原来那个不带参数的装饰器基础上之上在最外层套一个函数,该函数中定义一个参数,然后嵌套函数中引用该参数即可实现。从下图看出,我只是把里面那个函数改了一下名字,其余和原来不带参数的装饰器是一样的。有没有觉得这样更灵活?
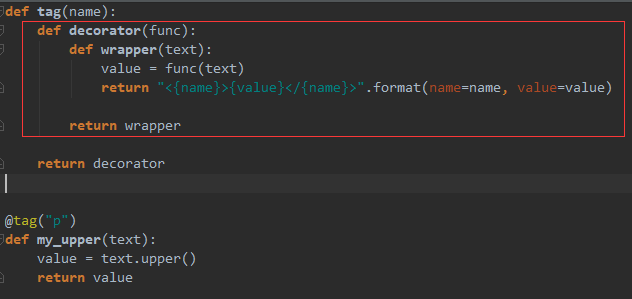
当然,装饰器不仅可以修饰函数,还可以修饰类。
娱乐时间
最后留给大家一个问题,给函数实现一个日志记录功能,日志里面记录函数名,函数执行所花的时间,通过指定参数控制日志级别,第一个写出来且正确的读者可以找我领取10元红包。考虑到代码在留言区显示不好好,你可以使用 https://gist.github.com/ 然后直接回复代码链接就可以。(此活动仅在公众号有效)
关注公众号「Python之禅」,回复「1024」免费获取Python资源
